Feature Selection Based on Mutual Information Gain for Classification and Regression
In today’s world, massive amounts of data are generated. Data from various sources are collected and used for modeling. The core aspect of any machine learning process would be to understand the data and its attributes. Due to the immense data that is being obtained, we couldn’t find the real underlying meaning behind the data and its attributes. People who deal with data need to understand what is mainly present in it. There are of course several attributes present in the data but what are the important ones that are most needed for analysis is the real deal here.
Feature selection is a vital process in Data cleaning as it is the step where the critical features are determined. Feature selection not only removes the unwanted ones but also helps us find the most relevant ones which help us increase the performance of our model. This blog describes an interesting feature selection technique which is Feature Selection based on Mutual information(Entropy) Gain which can be performed on classification and regression problems as well. It is a univariate filtering method which that gives better accuracy to the model. Since in univariate methods the feature importance is calculated separately instead of groups, so what happens is that the top 10 performing variables don’t perform well when grouped like in other methods, which ends up in choosing suboptimal features. But univariate filtering methods are quite fast which can be used as screening which leads to better accuracy and less training time.
Like all other feature selection techniques, this also aims to reduce the size of the input feature set and at the same time to retain the class discriminatory information for classification problems. Feature reduction can reduce the complexity of the problem or its computational time and even lead to an improvement in the model accuracy.
Mutual Information(MI)
Mutual Information estimates mutual information for fixed categories like in a classification problem or a continuous target variable in regression problems. Mutual Information works on the entropy of the variables.
Mutual information(MI)between two random variables is a non-negative value,which measures the dependency between the variables .It is equal to zero if and only if two random variables are independent ,and higher values mean higher dependency
In short, it is the amount of information one variable gives about the other.
Let us take two random variables there mutual information between them will be zero if and only if the variables are completely independent otherwise the mutual information between them would be symmetric and non-negative.
The mutual information between two random variables X and Y can be stated formally as follows:
- I(X ; Y) = H(X) — H(X | Y)
Where I(X; Y) is the mutual information for X and Y, H(X) is the entropy for X, and H(X | Y) is the conditional entropy for X given Y. The result has the units of bits(zero to one).
Mutual information is a measure of dependence or “mutual dependence” between two random variables. As such, the measure is symmetrical, meaning that I(X; Y) = I(Y; X).
Entropy in chemistry is defined as randomness. Here Entropy quantifies how much information there is in a random variable. So mutual information helps in reducing the entropy.
sklearn.feature_selection.mutual_info_classif
sklearn.feature_selection.mutual_info_regression
These are the two libraries provided by sklearn for using mutual information
Let’s start with Mutual Information Classification
import pandas as pd
df=pd.read_csv('wine.csv')
df.head()I’m using the wine dataset here.It contains 14 columns from which we are going to select the top 5 features
from sklearn.model_selection import train_test_split
X_train,X_test,y_train,y_test=train_test_split(df.drop(labels=['Wine'], axis=1),
df['Wine'],
test_size=0.3,
random_state=0)from sklearn.feature_selection import mutual_info_classif
mutual_info = mutual_info_classif(X_train, y_train)
mutual_info

mutual_info = pd.Series(mutual_info)
mutual_info.index = X_train.columns
mutual_info.sort_values(ascending=False)
mutual_info.sort_values(ascending=False).plot.bar(figsize=(20, 8))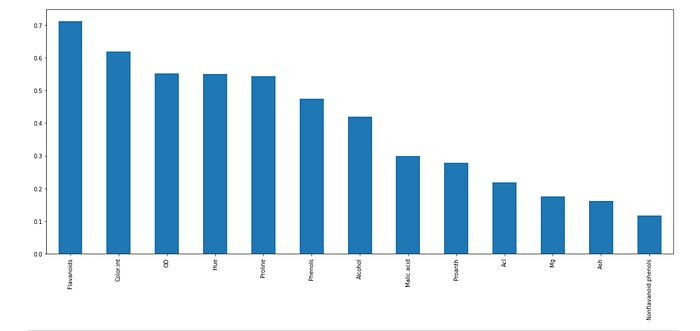
From the graph, we can infer that the flavonoids are having the highest mutual information gain(0.71) then color .int(0.61) followed by OD(0.55), and so on. So flavanoids give 70% of the information about the target variable wine in this case. To select the top features we use another library called SelectKBest which picks up the top K features. There is also an option to pick up the top percentile of features. Here we select only the top 5 features.
from sklearn.feature_selection import SelectKBest
sel_five_cols = SelectKBest(mutual_info_classif, k=5)
sel_five_cols.fit(X_train, y_train)
X_train.columns[sel_five_cols.get_support()]
So these are the top five features that give the most information about the target variable.
Now with Mutual Information Regression
import pandas as pd
housing_df=pd.read_csv('housing_data.csv')
housing_df.head()For regression, I’m using the housing data set which is available in Kaggle https://www.kaggle.com/c/house-prices-advanced-regression-techniques/data
It contains 81 columns which is a mixture of numerical and categorical columns. For this example, we’ll just use the numerical columns.
from sklearn.model_selection import train_test_split
X_train,X_test,y_train,y_test=train_test_split(housing_df.drop(labels=['SalePrice'], axis=1),
housing_df['SalePrice'],
test_size=0.3,
random_state=0)from sklearn.feature_selection import mutual_info_regression
mutual_info = mutual_info_regression(X_train.fillna(0), y_train)
mutual_info
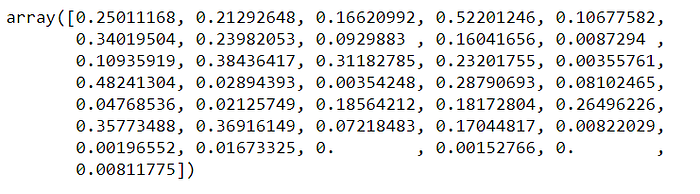
mutual_info = pd.Series(mutual_info)
mutual_info.index = X_train.columns
mutual_info.sort_values(ascending=False)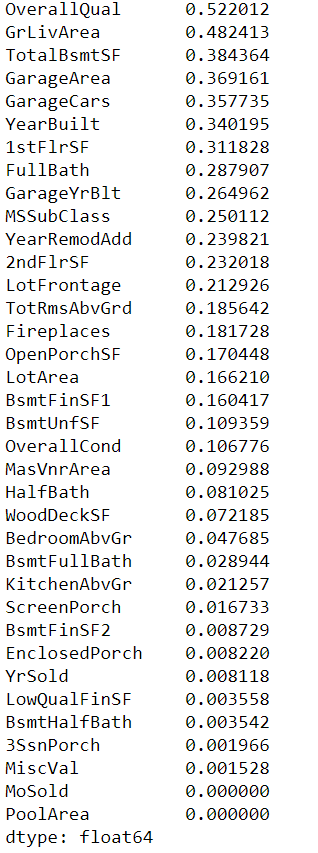
mutual_info.sort_values(ascending=False).plot.bar(figsize=(15,5))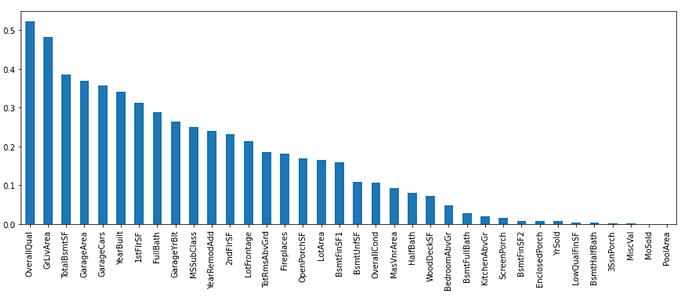
From the graph, we can infer that OverallQual is having the highest mutual information gain(0.52) then GrLivArea(0.48) followed by TotalBsmtSF(0.39), and so on. So OverallQual gives 50% of the information about the target variable sales price in this case. If we would have taken into account the categorical features some features may have given more information about the target variable. As explained early about SelectKbest, here we are going to use it to get the variables that contribute to the top 20 percentile.
from sklearn.feature_selection import SelectPercentile
selected_top_columns = SelectPercentile(mutual_info_regression, percentile=20)
selected_top_columns.fit(X_train.fillna(0), y_train)
selected_top_columns.get_support()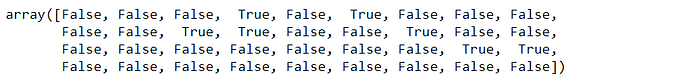
X_train.columns[selected_top_columns.get_support()]
So these are the features in the top 20th percentile, which means that after GarageArea the remaining features which are 80% have a dependence of at least less than that of GarageArea.
Thank you!!
